

I met Steve Wozniak at a talk he gave. I asked him what he thought about the Singularity (which is when the machines take over the world, very roughly speaking), and he talked with me about it for a minute. He was really cool! He even gave me his business card, which is made of titanium and can cut steak (seriously!).
I asked him to sign my copy of his book iWoz, and he inscribed it for me:
Christian, When the computers takeoffover, you will be missed.
-- Woz



The University of Florida Student Infosec Team competed in the Leet More CTF 2010 yesterday. It was a 24-hour challenge-based event sort of like DEFCON quals. Ian and I made the team some ridiculous Team Kernel Sanders shirts at our hackerspace just before the competition started. The good colonel vs. Lenin: FIGHT!
Here’s a walkthrough/writeup of one of the challenges.
One challenge at yesterday’s CTF was a seemingly-impossible SQL injection worth 300 points. The point of the challenge was to submit a password to a PHP script that would be hashed with MD5 before being used in a query. At first glance, the challenge looked impossible. Here’s the code that was running on the game server:
The only injection point was the first mysql_query(). Without the
complication of MD5, the vulnerable line of code would have looked like this:
$r = mysql_query("SELECT login FROM admins WHERE password = '" . $_GET['password'] . "'");If the password foobar were submitted to the script, this SQL statement would
be executed on the server:
SELECT login FROM admins WHERE password = 'foobar'
That would have been trivial to exploit. I could have submitted the password '
OR 1 = 1; -- instead:
SELECT login FROM admins WHERE password = '' OR 1 = 1; -- '
…which would have returned all the rows from the admins table and tricked
the script into granting me access to the page.
However, this challenge was much more difficult than that. Since PHP’s md5()
function was encrypting the password first, this was what was being sent to the
server :
SELECT login FROM admins WHERE password = '[output of md5 function]'
So how could I possibly inject SQL when MD5 would destroy whatever I supplied?

The trick in this challenge was that PHP’s md5() function can return its
output in either hex or raw form. Here’s md5()’s method signature:
string md5( string $str [, bool $raw_output = false] )
If the second argument to MD5 is true, it will return ugly raw bits instead
of a nice hex string. Raw MD5 hashes are dangerous in SQL statements because
they can contain characters with special meaning to MySQL. The raw data could,
for example, contain quotes (' or ") that would allow SQL injection.
I used this fact to create a raw MD5 hash that contained SQL injection code.
In order to spend the least possible time brute forcing MD5 hashes, I tried to think of the shortest possible SQL injection. I came up with one only 6 characters long:
'||1;#
I quickly wrote a C program to see how fast I could brute force MD5. My netbook could compute about 500,000 MD5 hashes per second using libssl’s MD5 functions. My quick (and possibly wrong) math told me every hash had a 1 in 28 trillion chance of containing my desired 6-character injection string.
So that would only take 2 years at 500,000 hashes per second.
If I could shorten my injection string by even one character, I would reduce the number of hash calculations by a factor of 256. After thinking about the problem for a while and playing around a lot with MySQL, I was able to shorten my injection to only 5 characters:
'||'1
This would produce an SQL statement like this (assuming my injection happened
to fall in about the middle of the MD5 hash and pretending xxxx is random
data):
SELECT login FROM admins WHERE password = 'xxx'||'1xxxxxxxx'
|| is equivalent to OR, and a string starting with a 1 is cast as an
integer when used as a boolean. Therefore, my injection would be equivalent to
this:
SELECT login FROM admins WHERE password = 'xxx' OR 1
By Just removing a single character, that got me down to 2.3 days' worth of calculation. Still not fast enough, but getting closer.
Since any number from 1 to 9 would work in my injection, I could shorten my
injection string to just '||' and then check to see if the injection string
were followed by a digit from 1 to 9 (a very cheap check). This would
simultaneously reduce my MD5 calculations by a factor of 256 and make it 9
times as likely that I’d find a usable injection string.
And since || is the same as OR, I could check for it too (2x
speedup) and all its case variations (16x speedup). Running my program on a remote dual-core desktop instead of my netbook got me another 10x speedup.
After computing only 19 million MD5 hashes, my program found an answer:
content: 129581926211651571912466741651878684928 count: 18933549 hex: 06da5430449f8f6f23dfc1276f722738 raw: ?T0D??o#??'or'8.N=?
So I submitted the password 129581926211651571912466741651878684928 to the
PHP script, and it worked! I was able to see this table:
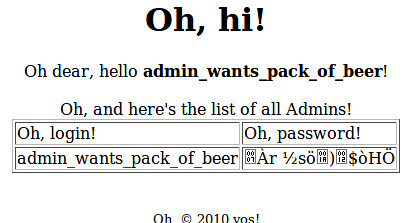
The last step of the challenge was to turn the MD5 hash into a password. I
could have used a brute forcer like John, but instead I just searched Google.
The password had been cracked by opencrack.hashkiller.com and was 13376843.

Recently H.D. Moore discovered a serious vulnerability in the widespread VxWorks 5.x operating system (or at least rediscovered it, expanded upon it, and publicized it). I was lucky enough to be one of the sixty people who saw his DEFCON 18 skytalk on the subject. He released information about the vulnerability to the public on August 2nd, 2010.
In addition to the main vulnerability (the fact that many vendor implementations of VxWorks 5.x had a publicly-accessible debug service running on port 17185), H.D. Moore discovered that the default VxWorks password hashing algorithm was insecure. He said he would release much more information about it one month from the initial release, which would mean September 2nd, 2010.
That was too long a wait for me, so I started working on the problem soon after I got home from DEFCON, and I was successful in finding the weakness H.D. talked about. I’ve also written a tool which can turn any password hash into a workalike password (i.e., a password different from the original password that produces the same hash), and another tool which scans VxWorks memory dumps for password hashes and reveals the workalike password for each one.
Although I’ve completed this work in early August, I have decided to follow the same release schedule that H.D. Moore has committed to, so this post is set to publish at midnight on September 2nd. I’m sure that I’ve only discovered part of what he will reveal on that day.
By default, passwords in VxWorks 5.x are hashed using a really stupid one-way hashing mechanism. I don’t understand why the VxWorks developers didn’t use a stronger hash. MD5 was popular as a one-way hash when VxWorks 5.x was being written, but they didn’t use it. Instead, they created their own hash, what H.D. Moore called a “Bob the Wizard” hash at the skytalk.
The meat of VxWorks password hashing algorithm is a checksumming step where each byte of the plaintext (the password to be hashed) is multiplied by and then XOR’d with its position in the string, and added to an accumulator. It looks like this in C (modified slightly from the original source for clarity):
checksum = 0; for (ix = 0; ix < strlen(plaintext); ix++) /* sum the string */ checksum += (plaintext[ix]) * (ix+1) ^ (ix+1);
Next, this checksum (an integer) is multiplied by a magic number and turned into a string in decimal:
sprintf (hash, "%u", (long) (checksum * 31695317)); /* convert interger
to string */(The lulzy typo in interger is original.)
The final step of computing a hash is doing a character substitution for each byte in the string:
for (ix = 0; ix < strlen (hash); ix++)
{
if (hash[ix] < '3')
hash[ix] = hash[ix] + '!'; /* arbitrary */
if (hash[ix] < '7')
hash[ix] = hash[ix] + '/'; /* arbitrary */
if (hash[ix] < '9')
hash[ix] = hash[ix] + 'B'; /* arbitrary */
}This character-substitution step really has no point other than making the hash
look “hashlike.” It simply converts decimal digits to letters (except 9,
which isn’t changed). For example, it always converts 0 to Q, 1 to R,
2 to S, 3 to b, etc. The input string 0123456789 would come out as
QRSbcdeyz9 every time. It might look more like a bonafide hash of some sort,
but it’s not.
In the end, every VxWorks 5.x password hash is composed of the alphabet
QRSbcdeyz9 and is up to 10 characters long.
For any password hashing algorithm, if you can generate a list of all possible outputs, and you know the inputs that generated those outputs, then you can turn any given password hash into a workalike password. (This is also called “reversing” the hash.) For a hashing algorithm like MD5 or SHA1, doing this is infeasible; however, the VxWorks checksum space is so small that it’s possible to generate such a list pretty easily.
The weakness in the VxWorks hashing algorithm is the summing step (the first
step). For any output value of the summing step (checksum), it’s easy to
modify the input (plaintext) to produce an output incremented by one
(checksum + 1). This means you can start with an input that generates the
lowest possible checksum and then, by continuously generating subsequent
checksums, you can create a table of all possible output values and all the
input values needed to create them.
I started working on this approach, but very quickly realized that there is a simpler way to generate such a table that requires very little thinking!
The VxWorks hashing algorithm just happens to be so bad (because it crunches so large an input space into so small an output space), that randomly generating a few million input values generates nearly every possible output value. In my tests, this approach found a workalike password for 100% of dictionary words and more than 99.99% of random input strings composed of all legal input characters.
I’m releasing some Ruby scripts and a C program here:
This is what’s included:
vxworks_find_collision.rb, a handy command-line tool for using the library)I’m also releasing a precomputed hash table (lookup.txt) for use with #1 and #2.


































































Update 1: See the last section below (The Code) for my Ruby code.
Update 2: Yes, I've written a server that acts just like the real one and will post the code soon.
Update 3: Decompiled RankMe.class is here: RankMe.java
Update 4: The official t400 server source has been released.



The pt400 challenge was a game in which you had to correctly rank a set of 71 famous people (including hackers in both senses of the word [e.g., Kevin Mitnick, Richard Stallman], famous coders [e.g., Knuth], cryptographers [e.g., Bruce Schneier], etc.). I'll call them all hackers for simplicity.
The game client was a simple Java Swing app called RankMe. You run it from the command line and it connects to the game server. Then, it presents two hackers and you have to pick the better one. If you pick the wrong hacker, the message "Better luck next time!" pops up and the game exits. The ranking of hackers was chosen by DDTek, I think somewhat arbitrarily, and is consistent from game to game.
The first thing I tried was to analyze the game traffic with Wireshark. This was pretty fail. There was no JPEG/PNG/GIF/BMP data in the stream, and no understanding of the protocol immediately came to me. I could have spent more time analyzing it, but instead I decided to decompile the client with JD-GUI (http://java.decompiler.free.fr/). This worked perfectly and gave me RankMe.java, which was easy to read and understand. I discovered how the game protocol worked by reading this code.
The protocol is simple. Basically, the server sends two images to the client at a time, and after receiving each pair of images and displaying them to the user, the client sends back the user's guess. If the user is right, the client can download two new images. If the user is wrong, the server sends an error code and disconnects. If the user has guessed enough matches correctly, the server asks for the combination of guesses that won (a string of LRLR..). If the user correctly inputs that combination, the server sends a secret message which is the key for pt400.
My strategy for winning was simple. First, I needed to get the outcome of a bunch of matches so that I'd be able to predict future matches. To do that, I implemented the protocol in Ruby in a class called Game which could connect to the game server and play games forever, collecting match results in a file called gamelog. (The Game class played stupidly, always picking the left picture.) The server was able to run about one round a second, and I had about 3,000 match results by the time I was ready for the next step. The match results (gamelog) looked like this:
9032d9fc7f0eec084636a35a0a623e84b2ee91a0 beat 895de4c13c326b60730786288465f91b5e5ba982
61ed2a78cf49d8c7eaa598fcbd9805825fae291c beat b94386c69bb0f04efe15863c480a2ba73bb7895d
2aea1a34c5cea68d5dd0678f04749e956935a11f beat 7b2fc387378a45a70c9db5cd384d3729ece8b3e7
50232549de83970517f50a6956e905004534919b beat f2f84e9514243c187cda82828569994a49ca481b
6e29bc1551abebad76297c5e3028a14188298d77 beat 815fc7e20b430cb34e98b632e081c8cfc0cbf9fa (I uniquely identified each hacker by the SHA1 hash of his picture. For example, ac1dburn was ab74176394caeb1158df9c4d9fac004fff27377a, and Tsutomu Shimomura was 39ddc6e687b0cd8255ea44a0a9a7b2cb88601454.)
The next step was to write an extension of the Game class called SmartGame which knew the results of all the matches and, given two hackers, could predict which one would win the match. Here's the prediction logic:

My original plan for SmartGame was to have it learn from the game as it played; however, it turned out that having a gamelog of 3,000 matches made this unnecessary. SmartGame was able to pick the correct hacker 100% of the time. It could connect to the server and win in less than 30 seconds (or maybe a little longer, but it was fast).
Update: I updated my code to learn from the game as it's played, just because it was an easy change.
The secret key was None hold a candle to Bessie the sh33p!
My pt400 solver is written in Ruby. It's messy. Sorry for the delay in putting it up. I meant to do it right after quals.
http://github.com/cvonkleist/defcon18quals/tree/master/pt400/
Check it out of Github (or just download protocol.rb and smart.rb). To run it, do this:
]]>I was talking to someone today who knew about rsync's bandwidth control, but not about scp's. Yep, they both have it.
For rsync, you specify the bandwidth limit it KB/s.
rsync --bwlimit 200 foo server:bar
My common usage is:
rsync -avz -e ssh --bwlimit 200 --progress foo server:bar
For scp, you specify the limit in Kb/s (kilobits vs. kiloBytes).
scp -l 1600 foo server:bar
You can make SSH much faster with the ControlMaster configuration directive. When enabled, only the first SSH connection to a server will incur slow connection overhead. Each additional connection will simply reuse the first connection via a tunnel.
This is especially useful when using command-line completion over SSH (using zsh, for example). Using tab completion on a predicate like scp gibson:www/ht will result in a multi-second delay each time, but with SSH ControlMaster connections, the delay is sub-second.
Just add this to your ~/.ssh/config:
Host * ControlPath /tmp/%r@%h:%p ControlMaster auto
That's it. Now your first SSH connection will automatically act as a ControlMaster. Each subsequent connection will be almost instantaneous. In my extremely scientific sample size of one host-server pair, this made subsequent connections about 16 times as quick (0.1 seconds to connect instead of 1.6).
]]>

About a year ago I wrote a script that crawled my Twitter network and made me follow lots of new people. Then it waited 24 hours to see if they followed me. If they did, I kept them in my list; otherwise, I chopped them. After a couple of days I had almost 600 followers. I just did this for fun, and I knocked it off after a couple of days for fear of being banned.
I wish I'd recorded stats from the beginning of the experiment, but I only started recording them in August (2009). This is what it looks like so far.
]]>This is a method I use when working with slow ruby scripts that operate on huge datasets.
It caches the return value of a block of extremely slow code in a file so that subsequent runs are fast.
It's indispensable to me when doing edit-debug-edit-debug-edit cycles on giant datasets.
]]>